初探WebMagic
»爬虫目录:
因为新的实习是做爬虫相关,于是最近研究了一下业界有名的java爬虫框架,WebMagic。WebMagic作者声称目标是要做一个java语言web爬虫教科书般的实现(我相信WebMagic已经做到了)。
总体架构
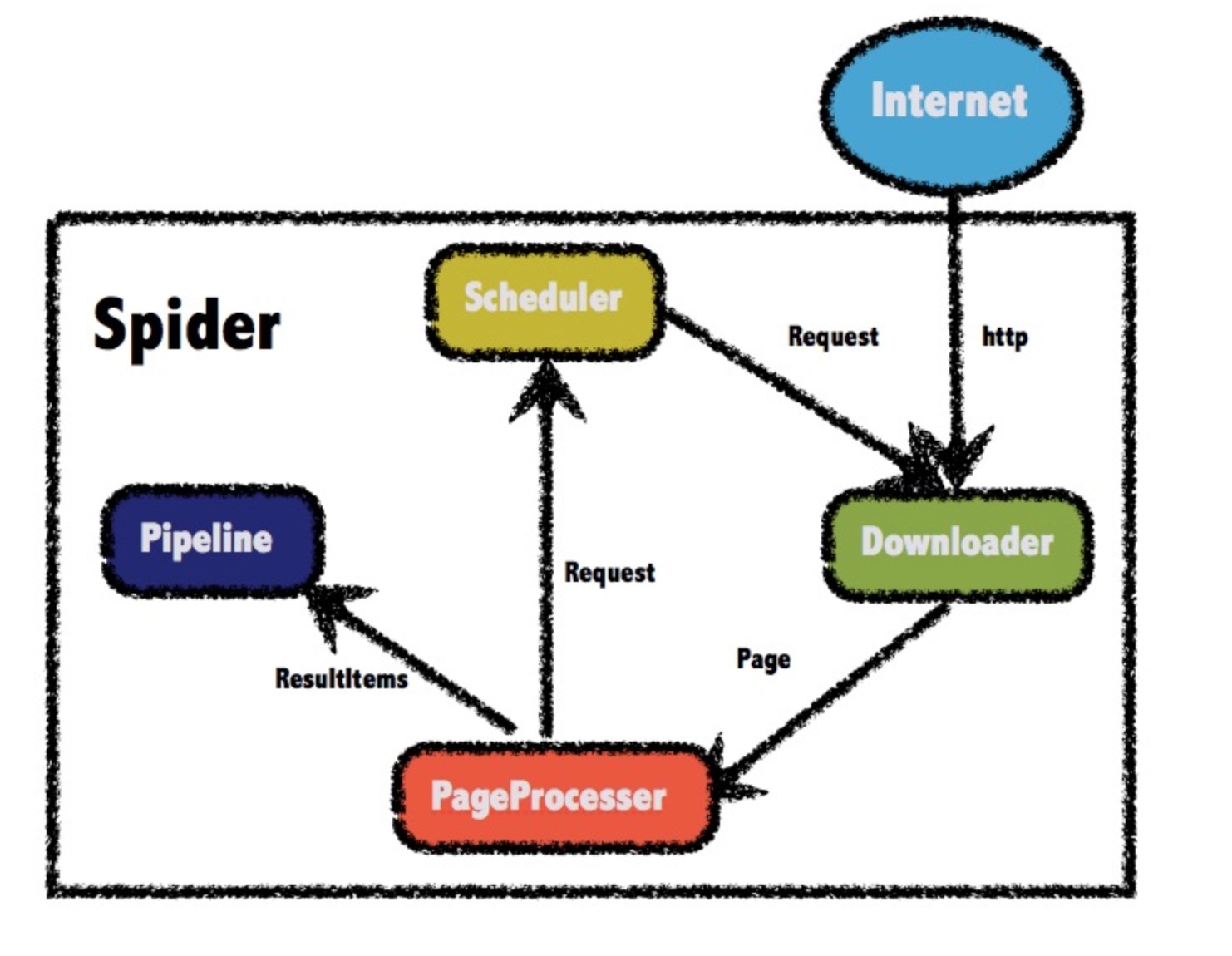
其核心组件是:
Scheduler:一个请求队列,用来存放带爬取的请求,默认使用LinkedBlockQueue实现
Downloader:下载器,根据请求下载页面
PageProcesser:处理页面,得到想要的resultItem,生成后续请求
Pipeline:处理resultItem
各个组件通过Spider对象组合。
总体来说,WebMagic架构十分清晰,并且很简单,各个组件分工明确,确实是一个教科书版的实现。
启动过程
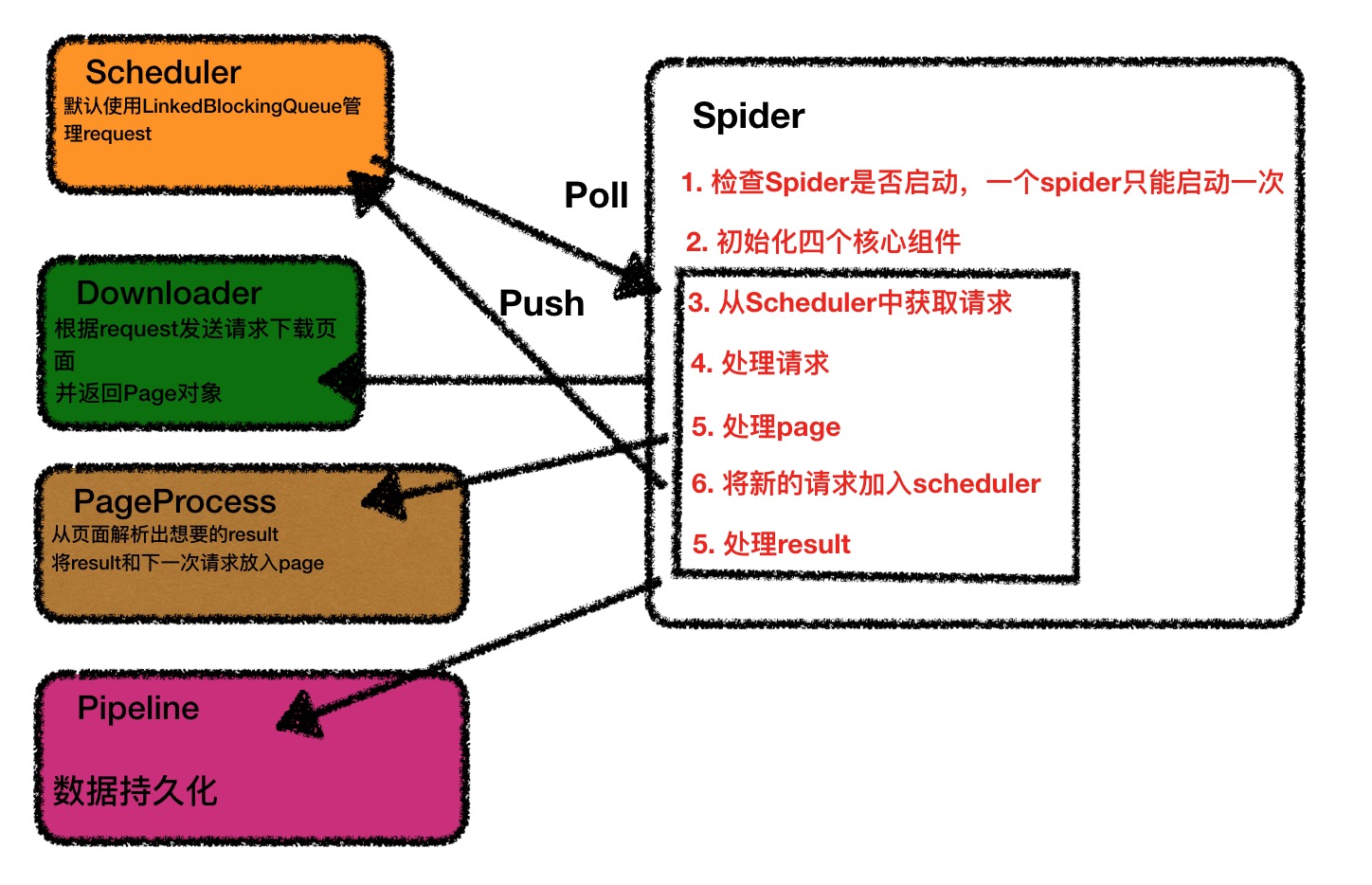 使用过程中,一般只需要自己实现特定的PageProcesser,和Pipeline即可
使用过程中,一般只需要自己实现特定的PageProcesser,和Pipeline即可
通过追踪源码,其核心逻辑都在Spider这个类中。
爬取百度贴吧实战
包结构
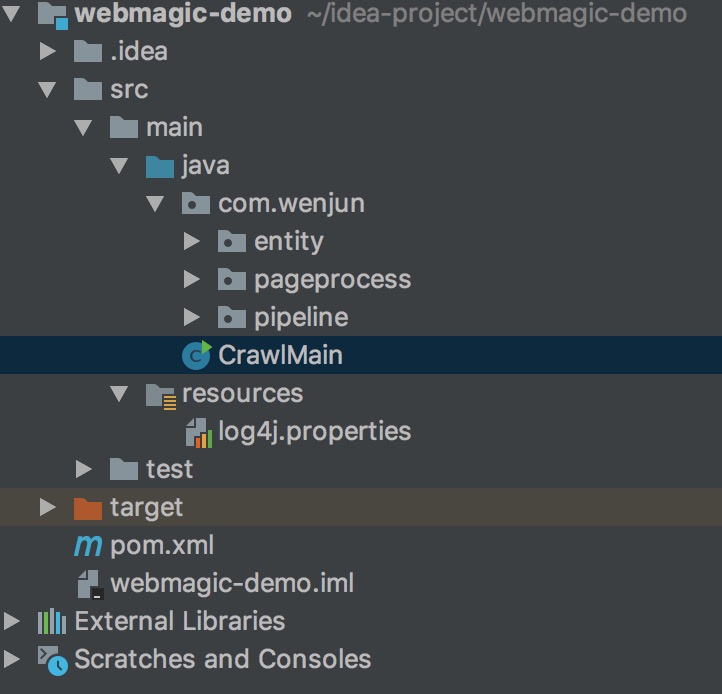
主类,构造一个Spider,启动即可
import com.wenjun.pageprocess.BaiduTiebaPageProcess;
import com.wenjun.pipeline.BaiduTiebaPipeline;
import us.codecraft.webmagic.Spider;
/**
* @Author: ruanwenjun
* @CreateDate: 2018/11/9 18:33
*/
public class CrawlMain {
public static void main(String[] args) {
Spider.create(new BaiduTiebaPageProcess())
.addPipeline(new BaiduTiebaPipeline())
.addUrl("http://tieba.baidu.com/f?ie=utf-8&kw=%E4%B8%AD%E5%8D%97%E5%A4%A7%E5%AD%A6&fr=search&red_tag=a1362091063")
.thread(Runtime.getRuntime().availableProcessors())
.start();
}
}
解析页面,使用Xpath解析
package com.wenjun.pageprocess;
import com.wenjun.entity.CSUEntity;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.ArrayList;
import java.util.List;
public class BaiduTiebaPageProcess implements PageProcessor {
private Logger logger = LoggerFactory.getLogger(BaiduTiebaPageProcess.class);
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public void process(Page page) {
List<String> titles = page.getHtml().xpath("//ul[@id='thread_list']/li[@class='j_thread_list clearfix']/div[1]/div[2]/div[1]/div[1]/a/text()").all();
List<String> comments = page.getHtml().xpath("//ul[@id='thread_list']/li[@class='j_thread_list clearfix']/div[1]/div[1]/span/text()").all();
List<String> authors = page.getHtml().xpath("//ul[@id='thread_list']/li[@class='j_thread_list clearfix']/div[1]/div[2]/div[1]/div[2]/span[1]/span[1]/a/text()").all();
logger.info("this page have {} title", titles.size());
List<CSUEntity> list = new ArrayList<CSUEntity>(titles.size());
for (int i = 0; i < titles.size(); i++) {
try {
CSUEntity csuEntity = new CSUEntity();
csuEntity.setTitle(titles.get(i));
csuEntity.setCommentNum(Integer.parseInt(comments.get(i)));
csuEntity.setAuthor(authors.get(i));
list.add(csuEntity);
} catch (Exception e) {
logger.error(e.toString());
}
}
page.putField("list", list);
String nextUrl = page.getHtml().xpath("//div[@class='thread_list_bottom clearfix']/div[1]/a[@class='next pagination-item']/@href").toString().substring(18);
logger.info("next url is {}", nextUrl);
page.addTargetRequest(nextUrl);
}
public Site getSite() {
return site;
}
}
Pipeline:将数据写入mysql
package com.wenjun.pipeline;
import com.wenjun.entity.CSUEntity;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.List;
public class BaiduTiebaPipeline implements Pipeline {
private Logger logger = LoggerFactory.getLogger(BaiduTiebaPipeline.class);
public void process(ResultItems resultItems, Task task) {
List<CSUEntity> list = resultItems.get("list");
try (Connection connection = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/localhost",
"username",
"password")) {
PreparedStatement preparedStatement = connection.prepareStatement("INSERT INTO crawl_baidu_csu_tieba (author,title,comment_num) VALUES (?,?,?)");
logger.info("begin insert {} entity into mysql", list.size());
for (int i = 0; i < list.size(); i++) {
CSUEntity csuEntity = list.get(i);
try {
preparedStatement.setString(1, csuEntity.getAuthor());
preparedStatement.setString(2, csuEntity.getTitle());
preparedStatement.setInt(3, csuEntity.getCommentNum());
preparedStatement.execute();
} catch (Exception e) {
logger.error("insert into mysql error,author:{},title:{},comment_num:{}", csuEntity.getAuthor(), csuEntity.getTitle(), csuEntity.getCommentNum());
}
}
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
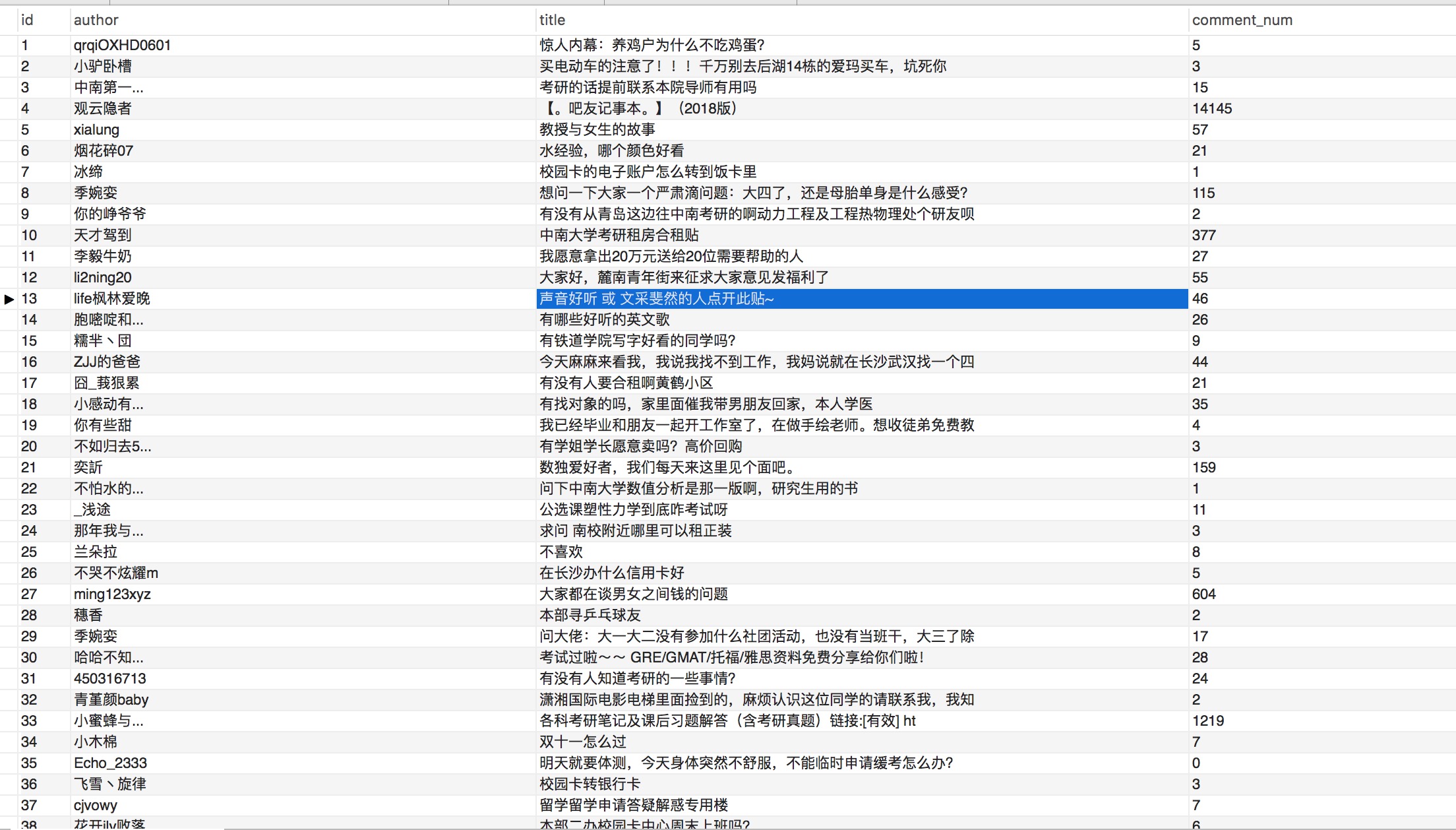
爬取结果如下: